History monoid
In mathematics and computer science, a history monoid is a way of representing the histories of concurrently running computer processes as a collection of strings, each string representing the individual history of a process. The history monoid provides a set of synchronization primitives (such as locks, mutexes or thread joins) for providing rendezvous points between a set of independently executing processes or threads.
History monoids occur in the theory of concurrent computation, and provide a low-level mathematical foundation for process calculi, such as CSP the language of communicating sequential processes, or CCS, the calculus of communicating systems. History monoids were first presented by M.W. Shields.[1]
History monoids are isomorphic to trace monoids (free partially commutative monoids) and to the monoid of dependency graphs. As such, they are free objects and are universal. The history monoid is a type of semi-abelian categorical product in the category of monoids.
Contents |
Product monoids and projection
Let
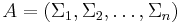
denote an n-tuple of alphabets 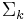 . Let
. Let 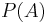 denote all possible combinations of finite-length strings from the alphabets:
denote all possible combinations of finite-length strings from the alphabets:
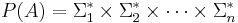
(In more formal language, is the Cartesian product of the free monoids of the . The superscript star is the Kleene star.) Composition in the product monoid is component-wise, so that, for
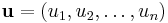
and
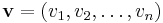
then
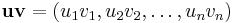
for all 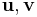 in . Define the union alphabet to be
in . Define the union alphabet to be
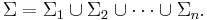
(The union here is the set union, not the disjoint union.) Given any string 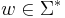 , we can pick out just the letters in some
, we can pick out just the letters in some 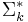 using the corresponding string projection
using the corresponding string projection 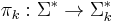 . A distribution
. A distribution 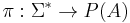 is the mapping that operates on with all of the
is the mapping that operates on with all of the 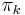 , separating it into components in each free monoid:
, separating it into components in each free monoid:
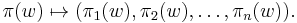
Histories
For every 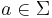 , the tuple
, the tuple 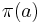 is called the elementary history of a. It serves as an indicator function for the inclusion of a letter a in an alphabet . That is,
is called the elementary history of a. It serves as an indicator function for the inclusion of a letter a in an alphabet . That is,
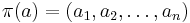
where
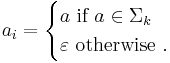
Here, 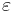 denotes the empty string. The history monoid
denotes the empty string. The history monoid 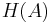 is the free monoid generated by elementary histories. It is clearly a submonoid of the product monoid . The elements of are called global histories, and the projections of a global history are called individual histories.
is the free monoid generated by elementary histories. It is clearly a submonoid of the product monoid . The elements of are called global histories, and the projections of a global history are called individual histories.
Connection to computer science
The use of the word history in this context, and the connection to concurrent computing, can be understood as follows. An individual history is a record of the sequence of states of a process (or thread or machine); the alphabet is the set of states of the process.
A letter that occurs in two or more alphabets serves as a synchronization primitive between the various individual histories. That is, if such a letter occurs in one individual history, it must also occur in another history, and serves to "tie" or "rendezvous" them together.
Consider, for example, 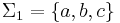 and
and 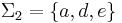 . The union alphabet is of course
. The union alphabet is of course 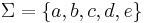 . The elementary histories are
. The elementary histories are 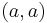 ,
, 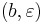 ,
, 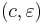 ,
, 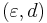 and
and 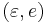 . In this example, an individual history of the first process might be
. In this example, an individual history of the first process might be 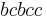 while the individual history of the second machine might be
while the individual history of the second machine might be  . Both of these individual histories are represented by the global history
. Both of these individual histories are represented by the global history 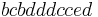 , since the projection of this string onto the individual alphabets yields the individual histories. In the global history, the letter
, since the projection of this string onto the individual alphabets yields the individual histories. In the global history, the letter 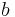 can be considered to commute with the letters
can be considered to commute with the letters 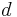 and
and 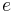 , in that these can be rearranged without changing the individual histories. Such commutation is simply a statement that the first and second processes are running concurrently, and are unordered with respect to each other; they have not (yet) exchanged any messages or performed any synchronization.
, in that these can be rearranged without changing the individual histories. Such commutation is simply a statement that the first and second processes are running concurrently, and are unordered with respect to each other; they have not (yet) exchanged any messages or performed any synchronization.
The letter 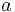 serves as a synchronization primitive, as its occurrence marks a spot in both the global and individual histories, that cannot be commuted across. Thus, while the letters and
serves as a synchronization primitive, as its occurrence marks a spot in both the global and individual histories, that cannot be commuted across. Thus, while the letters and 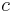 can be re-ordered past and , they cannot be reordered past . Thus, the global history
can be re-ordered past and , they cannot be reordered past . Thus, the global history 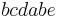 and the global history
and the global history 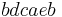 both have as individual histories
both have as individual histories 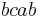 and
and 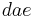 , indicating that the execution of may happen before or after . However, the letter is synchronizing, so that is guaranteed to happen after , even though is in a different process than .
, indicating that the execution of may happen before or after . However, the letter is synchronizing, so that is guaranteed to happen after , even though is in a different process than .
Properties
The history monoid is isomorphic to the trace monoid, and as such, is a type of semi-abelian categorical product in the category of monoids. In particular, the history monoid 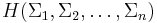 is isomorphic to the trace monoid
is isomorphic to the trace monoid 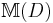 with the dependency relation given by
with the dependency relation given by
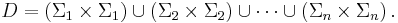
In simple terms, this is just the formal statement of the informal discussion given above: the letters in an alphabet can be commutatively re-ordered past the letters in an alphabet 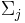 , unless they are letters that occur in both alphabets. Thus, traces are exactly global histories, and vice-versa.
, unless they are letters that occur in both alphabets. Thus, traces are exactly global histories, and vice-versa.
Notes
- ^ M.W. Shields "Concurrent Machines", Computer Journal, (1985) 28 pp. 449–465.
References
- Antoni Mazurkiewicz, "Introduction to Trace Theory", pp 3–41, in The Book of Traces, V. Diekert, G. Rozenberg, eds. (1995) World Scientific, Singapore ISBN 9810220588
- Volker Diekert, Yves Métivier, "Partial Commutation and Traces", In G. Rozenberg and A. Salomaa, editors, Handbook of Formal Languages, Vol. 3, Beyond Words, pages 457–534. Springer-Verlag, Berlin, 1997.